Code_obfuscation
前言
在编译器处理分析生成代码的时候,来 增加一些无用的代码、拆分代码块、使代码扁平化,进而提升静态分析的难度。
Chris Lattner 生于 1978 年,2005年加入苹果,将苹果使用的 GCC 全面转为 LLVM。2010年开始主导开发 Swift 语言。
- Xcode的编译器前端是clang,clang是llvm的一部分;而llvm本身是开源的,基于llvm 进行代码混淆的工具中,本人最终喜欢的马甲包混淆方案是用
Hikari,具体的用法看这里
- Clang 是 LLVM 的子项目,是 C,C++ 和 Objective-C 编译器 http://clang.llvm.org/docs/
- 其中的 clang static analyzer 主要是进行语法分析,语义分析和生成中间代码,当然这个过程会对代码进行检查,出错的和需要警告的会标注出来。
- lld 是 Clang / LLVM 的内置链接器,clang 必须调用链接器来产生可执行文件。
预处理 -> 词法分析 -> Token -> 语法分析 -> AST -> 代码生成 -> LLVM IR -> 优化 -> 生成汇编代码 -> Link -> 目标文件
- 符号化 (Tokenization)
- 宏定义的展开
- #include 的展开
- 语法和语义分析
- 解析树做语义分析
- 输出一棵抽象语法树(Abstract Syntax Tree* (AST))
- 生成代码和优化
- 对生成的中间码做优化
- LLVM IR 有三种表示格式,第一种是 bitcode 这样的存储格式,以 .bc 做后缀,第二种是可读的以 .ll,第三种是用于开发时操作 LLVM IR 的内存格式
- 生成特定目标代码
- 输出汇编代码
- 将汇编代码转换为目标对象文件。
- 将多个目标对象文件合并为一个可执行文件 (或者一个动态库)
可以用Clang做什么?
llvm/tools/clang/tools
- 那么,我们看到
LibTooling对代码的语法树有完全的控制,那么我们可以基于它去检查命名的规范,甚至做一个代码的转换,比如实现OC转Swift。clang-format对语法树有完全的控制权,作为插件注入到编译流程中,可以影响build和决定编译过程。目录:llvm/tools/clang/examples
- 可以用来定义一些编码规范,比如代码风格检查,命名检查等等
1\编译的完整步骤
- 1)编译信息写入辅助文件,创建文件架构 .app 文件
- 2)处理文件打包信息
- 3)执行 CocoaPod 编译前脚本,checkPods Manifest.lock
- 4)编译.m文件,使用 CompileC 和 clang 命令
- 5)链接需要的 Framework
- 6)编译 xib
- 7)拷贝 xib ,资源文件
- 8)编译 ImageAssets
- 9)处理 info.plist
- 10)执行 CocoaPod 脚本
- 11)拷贝标准库
- 12)创建 .app 文件和签名
2\clang 命令参数
- -x 编译语言比如objective-c
- -arch 编译的架构,比如arm7
- -f 以-f开头的。
- -W 以-W开头的,可以通过这些定制编译警告
- -D 以-D开头的,指的是预编译宏,通过这些宏可以实现条件编译
- -iPhoneSimulator10.1.sdk 编译采用的iOS SDK版本
- -I 把编译信息写入指定的辅助文件
- -F 需要的Framework
- -c 标识符指明需要运行预处理器,语法分析,类型检查,LLVM生成优化以及汇编代码生成.o文件
- -o 编译结果
3\xcode 编译器的相关设置
- Build Phases:构建可执行文件的规则
- 1)指定 target 的依赖项目,在 target build 之前需要先 build 的依赖。在 Compile Source 中指定所有必须编译的文件,
- 2)在 Link Binary With Libraries 里会列出所有的静态库和动态库,它们会和编译生成的目标文件进行链接。
- 3)build phase 还会把静态资源拷贝到 bundle 里。
- 4)可以通过在 build phases 里添加自定义脚本来做些事情,比如像 CocoaPods 所做的那样。
- Build Rules: 指定不同文件类型如何编译
- Build Settings : 在 build 的过程中各个阶段的选项的设置
4\Clang 使用的例子 : 从源码到可执行文件

clang -E main.m
- clang -fmodules -fsyntax-only -Xclang -dump-tokens main.m
- clang -fmodules -fsyntax-only -Xclang -ast-dump main.m
- 4、IR中间代码的生成:CodeGen 会负责将语法树自顶向下遍历逐步翻译成 LLVM IR,IR 是编译过程的前端的输出后端的输入
-O1,-O3,-Os。 还可以去写一些自己的Pass,这里需要解释一下什么是Pass。
- Pass就是LLVM系统转化和优化的工作的一个节点,每个节点做一些工作,这些工作加起来就构成了LLVM整个系统的优化和转化。
- 生成字节码 (LLVM Bitcode)
- 在Xcode7中默认生成bitcode就是这种的中间形式存在, 开启了bitcode,那么苹果后台拿到的就是这种中间代码,苹果可以对bitcode做一个进一步的优化,如果有新的后端架构,仍然可以用这份bitcode去生成
- clang -emit-llvm -c main.m -o main.bc
- clang -S -fobjc-arc main.m -o main.s
- clang -fmodules -c main.m -o main.o
- clang main.o -o main

8\整体的流程

5\Clang Static Analyzer静态代码分析: https://code.woboq.org/llvm/clang/
编译的概念(词法->语法->语义->IR->优化->CodeGen) 在 clang static analyzer 里到处可见。
- 关键字:语法中的关键字,if else while for 等。
- 标识符:变量名
- 字面量:值,数字,字符串
- 特殊符号:加减乘除等符号
6\CodeGen 生成 IR 代码
- 1)各种类,方法,成员变量等的结构体的生成,并将其放到对应的Mach-O的section中。
- 2)Non-Fragile ABI 合成 OBJCIVAR$_ 偏移值常量。
- 3)ObjCMessageExpr 翻译成相应版本的 objc_msgSend,super 翻译成 objc_msgSendSuper。
- 4)strong,weak,copy,atomic 合成 @property 自动实现 setter 和 getter。
- 5)@synthesize 的处理。
- 6)生成 block_layout 数据结构
- 7)block 和 weak
- 8)_block_invoke
- 9)ARC 处理,插入 objc_storeStrong 和 objc_storeWeak 等 ARC 代码。ObjCAutoreleasePoolStmt 转 objc_autorealeasePoolPush / Pop。自动添加 [super dealloc]。给每个 ivar 的类合成 .cxx_destructor 方法自动释放类的成员变量。
7\ IR 结构
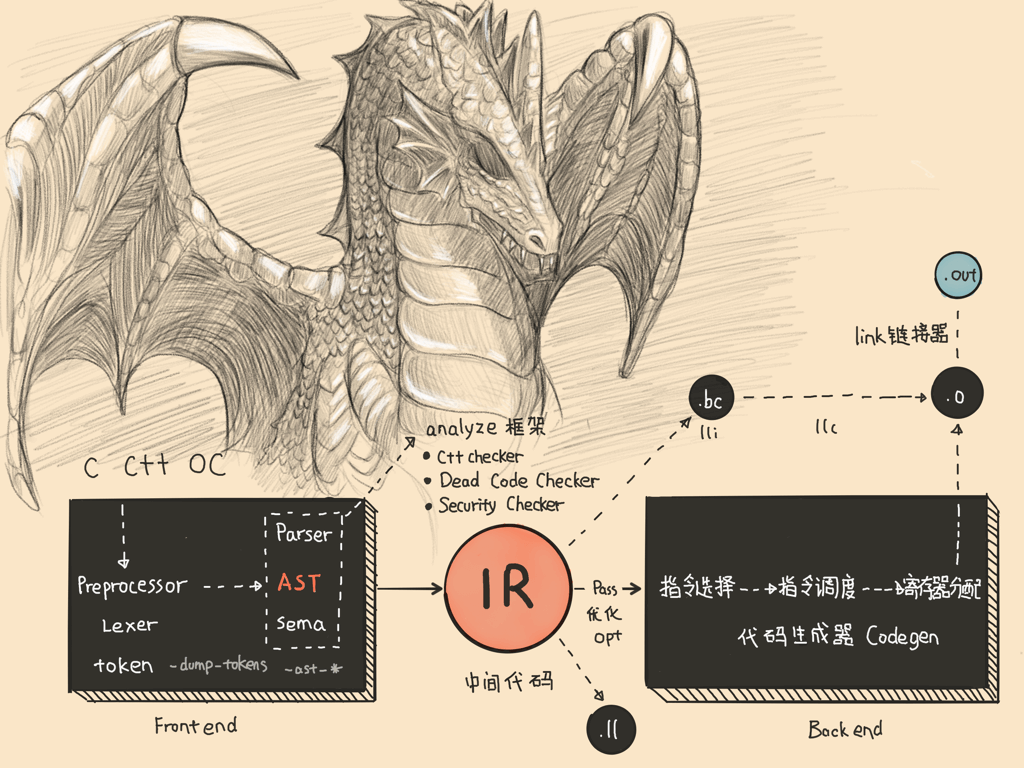
- llc 编译器是专门编译 LLVM IR 的编译器用来生成汇编文件。
- Driver
- Driver 是 Clang 面对用户的接口,用来解析 Option 设置,判断决定调用的工具链,最终完成整个编译过程。
- Translate:Translate 就是把相关的参数对应到不同平台上不同的工具。
- 每次编译后生成的 dSYM 文件 -
- dSYM 文件里存储了函数地址映射,这样调用栈里的地址可以通过 dSYM 这个映射表能够获得具体函数的位置。一般都会用来处理 crash 时获取到的调用栈 .crash 文件将其符号化
I \什么是LLVM?
llvm 是一系列 分模块和可重用的编译工具链,他提供了一种代码编写良好的中间表示(IR),可以作为多种语言的后端,还可以提供与编程无关的优化和针对多种CPU的代码生成功能。
- 前端:前端用来获取源代码然后将它转变为某种中间表示,我们可以选择不同的编译器来作为LLVM的前端,如gcc,clang。
- Pass(通常翻译为“流程”):Pass用来将程序的中间表示之间相互变换。一般情况下,Pass可以用来优化代码,这部分通常是我们关注的部分。
- 后端:后端用来生成实际的机器码
- The LLVM Project is a collection of modular and reusable compiler and toolchain technologies.
传统的编译器的架构如下

LLVM的架构如下

基于LLVM进行代码混淆时,只需关注中间层表示(IR)
基于LLVM,我们可以做什么?
- 做语法树分析,实现语言转换OC转Swift、JS or 其它语言,字符串加密。
- 编写ClangPlugin,命名规范,代码规范,扩展功能。
- 编写Pass,代码混淆优化。
II \ 安装编译LLVM
下载
编译
最新的LLVM只支持cmake来编译了,首先安装cmake。
编译:
- 打开Xcode的时候,选择
munually manage sechme,选择需要编译的Target(clang),接下来执行command+Rbuild/bin/目录下面找到生成的工具了。
- clang 的版本和Xcode的版本不一样,苹果在开源的LLVM中增加了自己的修改
III 、PassDemo
- pass 处理编译过程中代码的额转换以及优化工作。所有的pass都是pass的子类,不同的passs实现不同的作用,可以分别继承不同的pass类实现对应的功能
- ModulePass
- CallGraphSCCPass
- FunctionPass
- BasicBlockPass
- RegionPass
- LoopPass

配置编译环境
.../Transforms/CMakeLists.txt, 加上刚刚写的模块hello

编写代码

#include "llvm/IR/Function.h"#include "llvm/Pass.h"#include "llvm/Support/raw_ostream.h"
Hello World Pass (with getAnalysisUsage implemented)
使用opt 加载动态库,并指定参数
之前在代码中通过RegisterPass 注册了pass,现在可以准备一个测试用的源文件,通过opt -load 命令去加载动态库并指定参数hello
- path/to/build/deBug/bin/clang -emit-llvm -c test.mm -o test.bc
- 在Xcode中将opt的target添加到scheme中。编辑scheme的启动参数,按command+R执行。
- ../build/bin/opt -load ../build/lib/LLVMHello.dylib -simplepass < test.bc > after_test.bc
-time-passes参数用于输出pass的时间占比
其他操作
1、如果编写的pass用到了其他pass提供的函数功能,需要在getAnalysisUsage 中进行声明
getAnalysisUsage中进行调用
2、LLVMSimplePass(写的Pass只是把a+b简单的替换成了a-(-b),只是一个演示,怎么去写自己的Pass,并且作用于代码)
llvm-3.9.0.src/include/llvm/Transforms统一存放头文件
.../Transforms/LLVMBuild.txt, 加上刚刚写的模块Obfuscation.../Transforms/CMakeLists.txt, 加上刚刚写的模块ObfuscationLLVMSimplePass.dylib
将Pass加入PassManager管理
上面我们是单独去加载Pass动态库,这里我们将Pass加入PassManager,这样我们就可以直接通过clang的参数去加载我们的Pass了。
llvm/lib/Transforms/IPO/PassManagerBuilder.cpp添加头文件。populateModulePassManager这个函数中添加如下代码:LLVMBuild.txt中添加库的支持,否则在编译的时候会提示链接错误。具体内容如下:
基于Pass,我们可以做什么? 我们可以编写自己的Pass去混淆代码,以增加他人反编译的难度。

IV、OLLVM 源码分析,并从基于clang4.0 迁移到clang6.0
- 将
add_llvm_library修改为add_llvm_loadable_module编译成动态库,通过opt 加载调试(如果添加到passManager中,编译成静态库,同样可以通过opt加载调试)
- BogusControlFlow: 增加虚假的控制流程和无用的代码
- Flattening: 使代码扁平化
- Substitution: 增肌算术表达式的复杂度

编译生成动态库,分析BogusControlFlow
runOnFunction下断点,该方法会在处理方法的时候自动调用
addBogusFlow增加虚假控制流程addBogusFlow首先调用createAlteredBasicBlock复制原来的BasicBlock,然后修改其变量,引用并插入一些脏数据,接着创建一个恒为true的条件跳转到原来BasicBlock。false的分支跳转到复制的BasicBlock,复制的BasicBlock跳转回原来的BasicBlock。最后,创建一个恒为true的条件跳转到原BasicBlock的结束位置,false分支跳转到复制的BasicBlock。
BasicBlock *alteredBB = createAlteredBasicBlock(originalBB, *var3, &F);- 使用Graphviz 查看流程图,设置dot文件的默认打开方式。
- 调试过程使用
po originalBB->dump()打印对应的结果信息及浏览当前的流程图。- po F.viewCFG()
- build/Debug/llvm-dis test_after.bc -o test_after.ll` 将混淆处理之后的bitcode转换为可读的bitcode代码
opt -load ./lib/LLVMObfusaction.dylib -debug -flattening path/to/test.bc -o path/to/test_atfer.bc
Nothing to flatten直接返回;然后移除第一个BasicBlockRemove first BB.Get a pointer on the first BB接着判断第一个BasicBlock是不是条件判断或者分支,如果是就使用splitBasicBlock 将其分开,并移除第一个BasicBlock。Put all BB in the switch将之前保存的BasicBlock分别添加到switch分支中。
V 、替换Xcode编译器,在编译时将用带混淆工程的clang进行编译工程
要想通过clang 加载pass,就不能采用这种动态库方式(add_llvm_loadable_module),而是要编译成静态库(add_llvm_library)并加入passManager的管理机制定义的clang 传入的参数去调用pass
// Flags for obfuscation
PassManagerBuilder::PassManagerBuilder() {中初始化随机生成器// Initialization of the global cryptographicallysecure pseudo-random generatorvoid PassManagerBuilder::populateModulePassManager(中增加混淆的pass// Allow forcing function attributes as a debugging and tuning aid.
build/Debug/bin/clang test.mm -o test -mllvm -sub -fla -mllvm -bcf看看是否有混淆效果
- 开源的clang并不能识别:Xcode9 新增的swift_index_store_enable 参数


VI、静态库(StaticLib)混淆—基于编译器混淆的案例
编译器混淆是基于中间代码(bitcode)进行的。那么编译生成一个带bitcode的静态库是不是就可以提取其中的bitcode进行混淆?答案是也是
这样就不需要通过源文件进行编译了,只需要提供一个带bitcode的静态库文件即可进行混淆—商业机密,因此不需要得到源码也可以轻松的混淆了。哈哈哈
-fembed-bitcode参数__LLVM,__bitcode的section里面的bitcode代码提取出来
segedit ./StaticLib.o -extract "__LLVM" "__bitcode" result.bc
- /Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/bin/segedit
build/Debug/bin/clang -arch arm64 -isysroot /Applications/Xcode.app/Contents/Developer/Platforms/iPhoneOS.platform/Developer/SDKs -fobjc-arc -c result.bc -mllvm -bcf -mllvm -sub -mllvm -fla -o result.o- rm __.SYMDEF\ SORTED
- ar -crs result.a result.o
- ranlib result.a
- ranlib - add or update the table of contents of archive libraries
小结: 从静态库提出bitcode ,使用带有混淆功能的clang 重新编译bitcode进行混淆生成混淆之后的目标文件。并将目标文件进行打包成.a
思考题
将核心代码封装成静态库(包含bitcode的静态库),提供给我,进行混淆处理治理之后,再将混淆之后的静态库给他。—–目的是避免提供源代码给我。
接下来他们再将核心的静态库集成到app中进行上架。
- bitcode 是中间表示形式,常用于代码优化。
尝试使用/Users/devzkn/Library/Developer/Toolchains/Hikari.xctoolchain/usr/bin/clang进行混淆
build/Debug/bin/clang -arch arm64 -isysroot /Applications/Xcode.app/Contents/Developer/Platforms/iPhoneOS.platform/Developer/SDKs -fobjc-arc -c result.bc -mllvm -bcf -mllvm -sub -mllvm -fla -o result.o
See Also
- 马甲包混淆方案/#more
- https://github.com/zhangkn/obfuscator
- https://zhangkn.github.io/2018/03/Hopper/
- LLVM IR 有三种表示格式,第一种是 bitcode 这样的存储格式,以 .bc 做后缀,第二种是可读的以 .ll,第三种是用于开发时操作 LLVM IR 的内存格式
- 当虚拟内存系统进行映射时,segment 和 section 会以不同的参数和权限被映射。
- __TEXT segment 包含了被执行的代码。它被以只读和可执行的方式映射
- __DATA segment 以可读写和不可执行的方式映射。它包含了将会被更改的数据。
- __nl_symbol_ptr 和 __la_symbol_ptr,它们分别是 non-lazy 和 lazy 符号指针。
- 延迟符号指针用于可执行文件中调用未定义的函数,例如不包含在可执行文件中的函数,它们将会延迟加载。而针对非延迟符号指针,当可执行文件被加载同时,也会被加载。
- 深入剖析 iOS 编译 Clang / LLVM 视频
- 深入剖析 iOS 编译 Clang / LLVM 文章 Low Level Virtual Machine
- knpost
评论
发表评论